This is the first post in what’s going to be a multi post series exploring how MQTT can be leveraged in the cloud. The series will look at several different models for deploying applications in the cloud and how you can leverage MQTT as an event based protocol for those applications. This first post will be looking at using MQTT as unified event bus for heterogeneous service deployed using more traditional configuration managed services by looking at the OpenStack community infrastructure’s firehose effort.
MQTT
Before diving into firehose and why MQTT is used there it would to explain what MQTT is. MQTT is a machine to machine pub/sub protocol which is primarily targeted for IoT applications and sensor networks. It’s designed to be lightweight and work in environments where code size is a constraint or networking is unreliable or where bandwidth is at a premium. The protocol was originally written in 1999 and is now an ISO standard that is managed by the OASIS group.
MQTT is based on a centralized broker. Clients publish and/or subscribe to topics on the broker to send and receive messages to each other. There are a variety of different brokers both open and closed source available. On the client side there are bindings available for a lot of different languages and environments.
The interesting pieces of the MQTT protocol when it comes to firehose and similar applications running in a cloud environment are topics, quality of servicem and client persistence.
Topics
The most obvious thing that makes MQTT different from a lot of other is how topics work. All message topics in MQTT are hierarchical and dynamic. This means that a topic is only created at message publish time and are dynamically matched with any clients subscribed. When coupled with wild carding is when this gets really useful. This enables you to build applications that listens only to the subset of messages you are interested in.
For example, let’s say I was publishing messages from my laptop’s sensor I would use a topic schema like:
sensors/<hostname>/<sensor type>/<device id>
So if I wanted to publish a message with the SSD’s temperature, I would publish to a topic like:
sensors/sinanju/temperature/nvme0n1
Where sinanju is the laptop’s hostname. Now for a client subscribing you could subscribe to that exact topic and get message for just that one device. Or you could use wildcards to subscribe to multiple devices. For example, if you wanted all sensors from my laptop you would subscribe to:
sensors/sinanju/#
Which uses the multilevel wildcard ‘#’ to match any topics that start with “sensors/sinanju” in the hierarchy. Or if you wanted all temperature sensors on all devices you would subscribe to:
sensors/+/temperature/+
Which uses the single level wildcard ‘+’, which will match any field on that level of the hierarchy. You can see how powerful using a combination of a detailed hierarchy and the wildcards let you dynamically subscribe to only messages your application is interested in.
For more examples and some suggestions on building topic hierarchies these 2 links have more details:
https://www.hivemq.com/blog/mqtt-essentials-part-5-mqtt-topics-best-practices
https://mosquitto.org/man/mqtt-7.html
QoS
MQTT supports 3 levels of quality of service 0, 1, and 2. QoS level 0 means there is no guarantee on delivery, QoS level 1 means the message is guaranteed to be delivered at least once, but may be recieved more than once, and QoS level 2 means the message will be delivered once and only once. The interesting piece on QoS in MQTT is that it’s per message publish or per subscription. Meaning that when a client publishes a message that set it’s own QoS level for sending to the broker. Then when a client subscribes to a topic on a broker it sets QoS level for the subscription. These are independent from each other, meaning you can publish a message to a topic with QoS level 2 and subscribe to that topic with QoS level 0. This also means you can have an application hand pick the guarantees per message to optimize between the bandwidth and overhead for the individual messages if you need.
You can read more about QoS in MQTT here: https://www.hivemq.com/blog/mqtt-essentials-part-6-mqtt-quality-of-service-levels
Persistent Sessions
The last aspect of the MQTT protocol that really makes it useful for an application like firehose running in a cloud environment is persistent sessions. Normally when a client connects to a broker it specifies it subscribes to the topics it’s interested in, but when the client disconnects those topics are lost. However, a client can specify a clientId and when that is combined with the higher QoS levels the broker will queue up messages to ensure that even if the subscribing client disconnects it will receive those messages on reconnect. This way you can ensure a client will never miss a message even if you lose connectivity.
The details on this are quite specific and instead of rehashing them all here the hivemq blog has documented the details quite well here: https://www.hivemq.com/blog/mqtt-essentials-part-7-persistent-session-queuing-messages
Firehose
So with some background on what MQTT is and some of the strengths it brings to the table it’s time to take a look at the firehose. The OpenStack community’s infrastructure runs completely in the open to support the OpenStack community. This includes running things like the gerrit review system, the upstream CI system, and other services. It ends up being a very large infrastructure running over 40 different services on 250 servers (not counting hosts used for running tests) in OpenStack clouds which are donated by various OpenStack service providers. All of these services are managed using a combination of puppet to describe the configuration and packages and ansible to orchestrate running puppet on the different servers.
All of these services are generating events of some type, whether it’s the completion of a task, a user initiated action, a periodic status update, etc. Some of the services have native event streams but a lot of them don’t. The missing piece was a single place to handle the events from all of these different services. Right now if a service has an event stream at all it’s exposed as a separate thing implemented in it’s own way. For example, Gerrit‘s event stream is implemented as a command run via it’s ssh interface (which is inherently specific to gerrit). This is where firehose fits in, it provides a unified message bus for all the different services running in the community infrastructure. This gives both users and other applications a single place to go when they need to consume events from any infrastructure service.
We’ve documented how firehose is built and how to use it in the infra documentation: https://docs.openstack.org/infra/system-config/firehose.html. As that shows we’ve got a number of different services reporting events to the firehose and it’s pretty straightforward for anyone to subscribe to events. It’s even easy to do from JS natively in a browser like:
Which is subscribing to “#”, or all topics, and just printing the topic and payload colon separated. The code behind that is basically (just trimmed to work in my blog, the below is for a standalone page):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
<!doctype html> <html lang="en"> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> </head> <body> <div id="title"> <h1>MQTT Messages</h1> </div> <div class="content" style="height:240px;width:960px;border:1px solid #ccc;font:16px/26px Georgia, Garamond, Serif;overflow:auto;"> <pre class="msglog" id="msglog"></pre> </div> <script src="https://code.jquery.com/jquery-3.2.1.slim.min.js" integrity="sha384-KJ3o2DKtIkvYIK3UENzmM7KCkRr/rE9/Qpg6aAZGJwFDMVNA/GpGFF93hXpG5KkN" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.12.9/umd/popper.min.js" integrity="sha384-ApNbgh9B+Y1QKtv3Rn7W3mgPxhU9K/ScQsAP7hUibX39j7fakFPskvXusvfa0b4Q" crossorigin="anonymous"></script> <script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/js/bootstrap.min.js" integrity="sha384-JZR6Spejh4U02d8jOt6vLEHfe/JQGiRRSQQxSfFWpi1MquVdAyjUar5+76PVCmYl" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/paho-mqtt/1.0.1/mqttws31.js" type="text/javascript"></script> <script type="text/javascript"> var mqttHost = "firehose.openstack.org"; var client = new Paho.MQTT.Client(mqttHost, Number("80"), "client-" + Math.random()); // set callback handlers client.onConnectionLost = onConnectionLost; client.onMessageArrived = onMessageArrived; // connect the client client.reconnect = true; client.connect({onSuccess: onConnect}); // called when the client connects function onConnect() { // Once a connection has been made, make a subscription and send a message. console.log("onConnect"); client.subscribe("#"); } // called when the client loses its connection function onConnectionLost(responseObject) { if (responseObject.errorCode !== 0) { console.log("onConnectionLost:"+responseObject.errorMessage); } } // called when a message arrives function onMessageArrived(message) { console.log("onMessageArrived: "+message.destinationName + " " + message.payloadString); var content = message.destinationName + " " + message.payloadString + "\n"; var pre = $("#msglog"); pre.append(content); pre.scrollTop( pre.prop("scrollHeight") ); } </script> </body> </html> |
The documentation linked above has a lot of code examples in a bunch of different languages. So you can use those examples to experiment with the firehose locally.
In addition to documentation linked above we also have extensive schema documentation for the firehose. Which documents the schema for both the topics and message payloads for all the services, which can be found at: https://docs.openstack.org/infra/system-config/firehose_schema.html. This documents how messages are constructed for all the services publishing messages to the firehose. This should enable anyone to build off the messages in the firehose for anything they need.
While this provides a description of what the firehose is and gives an idea on how to use it, it’ll be valuable to also talk about how it’s constructed and take a look how well it’s working.
firehose.openstack.org
For firehose we run the mosquitto MQTT broker on a single server. It’s actually a fairly small machine with only 2 vCPUs, 2GB of RAM, and a 40GB disk. Despite being a modest machine there is no issue with handling the load from all the services reporting. For example a typically message rate is: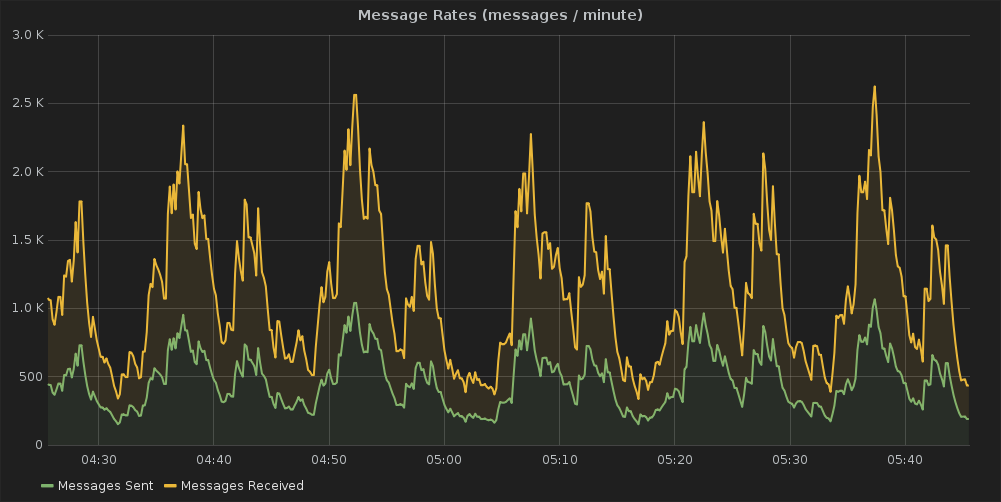 or you can see the current broker statistics at:
or you can see the current broker statistics at:
http://grafana.openstack.org/dashboard/db/mosquitto-status which was built using the mqtt_statsd project. Despite this message load it barely uses any resources Looking at the past month the CPU and RAM usage was minimal considering the amount of messages being published:
CPU Usage Ram Usage
Ram Usage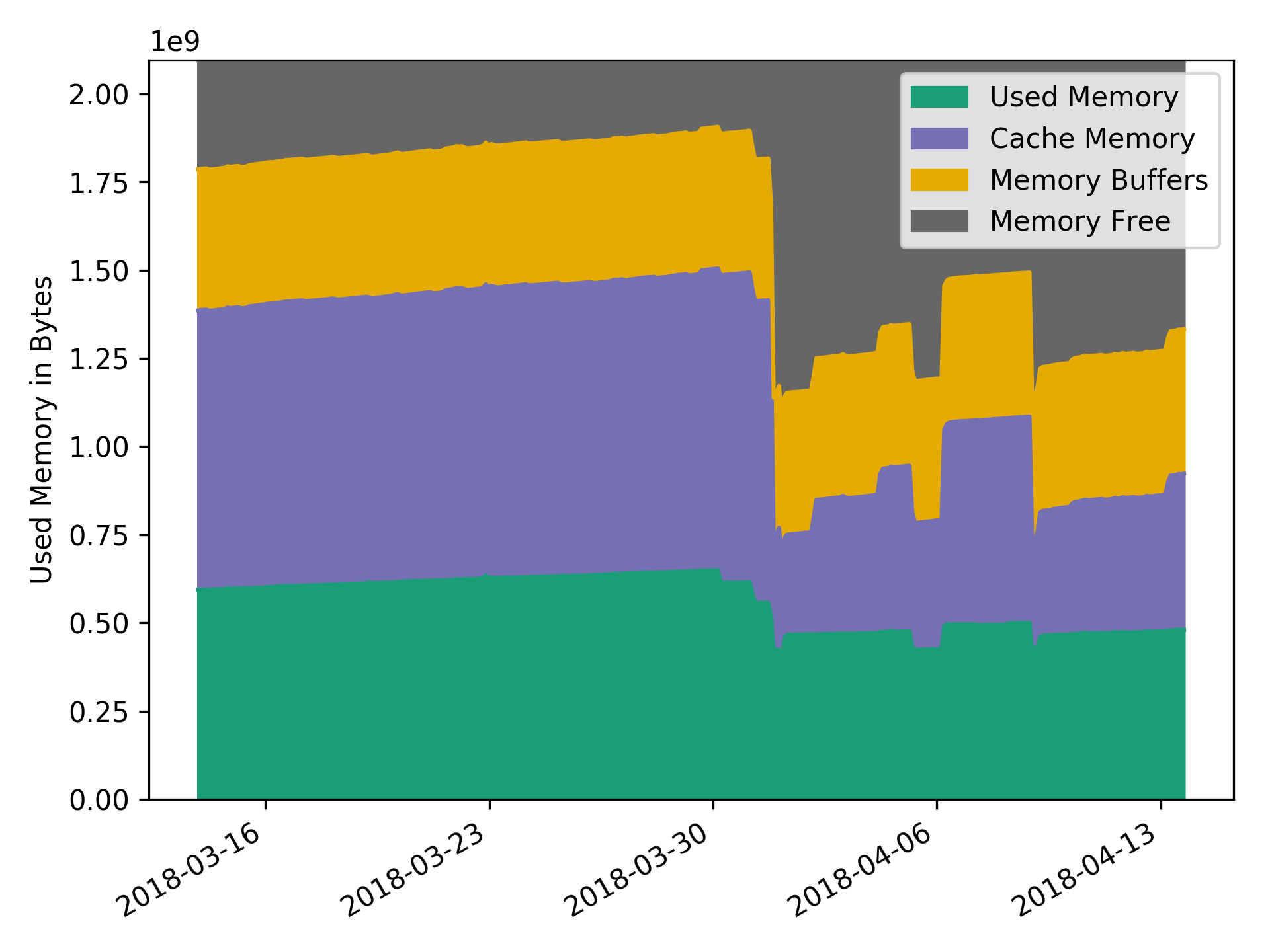 You can see the current numbers on cacti.openstack.org.
You can see the current numbers on cacti.openstack.org.
Load Testing
About a year ago when we started growing our usage of firehose we decided to do some manual load testing. We first tried to leverage the mqtt-bench project to do this, but unfortunately it’s not being actively maintained. So we ended up writing pymqttbench to do this task. When we did this load testing we were hindered by the bandwidth limitations of 200 Mbps for the server flavor we deployed. However despite hitting that hard wall limiting our testing we were able to see some interesting data.
So the first thing we looked at the total number of message we were processing during the load testing:
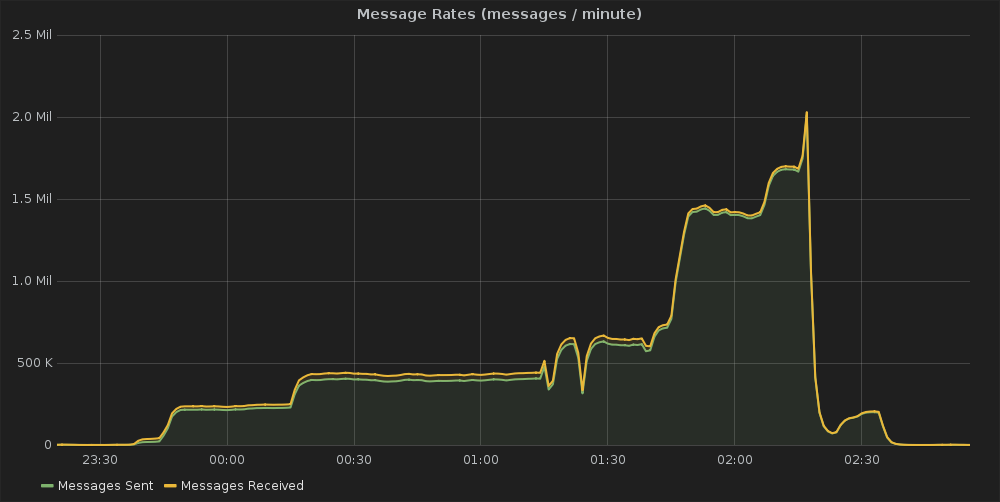 We ran the testing over the period of a few hours while slowly ratcheting up the number of messages we were and were able to peak at about 2 million messages per minute going through the broker before we realized we were hitting a bandwidth limit and stopped the testing. The interesting thing with this test was looking at the system load at the time. First the CPU usage:
We ran the testing over the period of a few hours while slowly ratcheting up the number of messages we were and were able to peak at about 2 million messages per minute going through the broker before we realized we were hitting a bandwidth limit and stopped the testing. The interesting thing with this test was looking at the system load at the time. First the CPU usage:
 This graph shows a spike in the CPU utilization topping out at about 30-35% during the load test. The interesting thing with this though, is that spike occurred about an hour before the peak data usage of the test. Our expectation going into the test was that the load would be coupled directly to the number of messages and subscribers. But this graph clearly shows the spike was independent of either of those. Then looking at the RAM usage during the test:
This graph shows a spike in the CPU utilization topping out at about 30-35% during the load test. The interesting thing with this though, is that spike occurred about an hour before the peak data usage of the test. Our expectation going into the test was that the load would be coupled directly to the number of messages and subscribers. But this graph clearly shows the spike was independent of either of those. Then looking at the RAM usage during the test:
 We ended up using more RAM (percentage wise) during the testing peaking at about 1.25 GB being used by Mosquitto. But the big spike corresponds to the CPU usage spike which occurred before the max message throughput. When you look at the RAM usage when we were at the max messages it was at about it’s lowest value, at between 250MB and 350MB.
We ended up using more RAM (percentage wise) during the testing peaking at about 1.25 GB being used by Mosquitto. But the big spike corresponds to the CPU usage spike which occurred before the max message throughput. When you look at the RAM usage when we were at the max messages it was at about it’s lowest value, at between 250MB and 350MB.
At some point we’ll have to revisit the load testing experiment. All this test showed was that the small server we have deployed is able to keep up with whatever load we throw at it, and have a large amount of headroom for more messages before we hit any limits of the small server we’re using, which admittedly was the goal of our testing. But, besides that it raised more questions than it answered about what those limits actually are, which is something we still need to investigate.
Conclusion
To tie everything together what has the firehose project shown us about using MQTT for applications in the cloud. The first thing is the lightweight nature of the protocol is a great fit for the cloud. In most cloud environments you pay for your resource utilization, so the less you use the less you have to pay. What firehose has demonstrated in this regard is that by using MQTT you can get away with minimal resource utilization and still have a solution that will work with a large load. Another key aspect is MQTT’s resiliency to unreliable networking. The old adage of treat your servers in the cloud like cattle not pets holds true. You can look at other aspects of OpenStack’s community infrastructure and see all sorts of failures. For example, http://status.openstack.org/elastic-recheck/index.html#1298006 tracks a failure in the CI system where a test node can’t talk to the git servers. That graph shows how frequently we’re encountering random networking issues in a cloud. We’ve been running firehose since Autumn 2016 and I can’t recall of any instances when a service or client lost it’s connection and wasn’t able to recover seamlessly. This is including several broker restarts for service upgrades and configuration changes. The last aspect here is because MQTT has been around for 20 years there is a large ecosystem that already exists around the protocol. This means regardless of how you’re building your application, or what language it’s written in, there is likely already support for using MQTT there. This means you don’t have to spend time reinventing the wheel to add support for using MQTT or you can leverage existing projects to do common functions with MQTT.
What this whole project has demonstrated to me is that the application requirements for IoT and remote sensor networks aren’t that dissimilar from writing applications in the cloud. The next post in this series will be looking at using MQTT in applications deployed on Kubernetes.